Research Design: Experimental Research
20 Experiment Basics
What Is an Experiment?
An experiment is a type of study designed specifically to answer the question of whether there is a causal relationship between two variables. In other words, whether changes in one variable (referred to as an independent variable cause a change in another variable (referred to as a dependent variable).
Experiments have two fundamental features. The first is that the researchers manipulate, or systematically vary, the level of the independent variable. The different levels of the independent variable are called conditions. For example, Werkman, Van Doorn & Van Ittersum (2022) told participants to eat as many cookies as they wanted during the watching of a video. The researchers manipulated two variables: unit size (amount of cookies) and serving size (size of cookies). This resulted in four conditions 1. small serving size, small unit size, 2. large serving size, small unit size, 3. small serving size, large unit size, 4. large serving size, large unit size. For a new researcher, it is easy to confuse variables with conditions, but it’s important to tell them apart: if you’re interested in the effect of serving large cookies, you need to compare it against something else (here: serving small cookies).
The second fundamental feature of an experiment is that the researcher exerts control over, or minimizes the variability in, variables other than the independent and dependent variable. These other variables are called extraneous variables. Werkman, Van Doorn & Van Ittersum (2022) [1]performed their study in the lab (a controlled environment), checked whether participants were hungry, had a cover story about having participants evaluate a short movie about a bike ride, and so on. They also randomly assigned their participants to conditions so that the four groups would be similar to each other to begin with. Notice that although the words manipulation and control have similar meanings in everyday language, researchers make a clear distinction between them. They manipulate the independent variable by systematically changing its levels and control other variables by holding them constant.
Manipulation of the Independent Variable
Again, to manipulate an independent variable means to change its level systematically so that different groups of participants are exposed to different levels of that variable, or the same group of participants is exposed to different levels at different times. For example, to see whether expressive writing affects people’s health, a researcher might instruct some participants to write about traumatic experiences and others to write about neutral experiences. The different levels of the independent variable are referred to as conditions, and researchers often give the conditions short descriptive names to make it easy to talk and write about them. In this case, the conditions might be called the “traumatic condition” and the “neutral condition.”
Notice that the manipulation of an independent variable must involve the active intervention of the researcher. Comparing groups of people who differ on the independent variable before the study begins is not the same as manipulating that variable. For example, a researcher who compares the health of people who already keep a journal with the health of people who do not keep a journal has not manipulated this variable and therefore has not conducted an experiment. This distinction is important because groups that already differ in one way at the beginning of a study are likely to differ in other ways too. For example, people who choose to keep journals might also be more conscientious, more introverted, or less stressed than people who do not. Therefore, any observed difference between the two groups in terms of their health might have been caused by whether or not they keep a journal, or it might have been caused by any of the other differences between people who do and do not keep journals. Thus the active manipulation of the independent variable is crucial for eliminating potential alternative explanations for the results.
Of course, there are many situations in which the independent variable cannot be manipulated for practical or ethical reasons and therefore an experiment is not possible. For example, economists are not free to perform experiments on a nation’s economy, and researchers doing researchers on subjects involving ethics or morality are not free to perform experiments that ask respondents to perform unethical or immoral acts. This means that, in some areas, experiments simply cannot be performed. However, this does not mean it is impossible to learn about about causal relationships in these fields, only that it must be done using other (such as quasi-experiments) approaches.
Independent variables can be manipulated to create two conditions and experiments involving a single independent variable with two conditions are often referred to as a single factor two-level design. However, sometimes greater insights can be gained by adding more conditions to an experiment. When an experiment has one independent variable that is manipulated to produce more than two conditions it is referred to as a single factor multi level design. For example, this would be the case for Werkman, Van Doorn & Van Ittersum (2021) had they only manipulated one variables (e.g. only cookie size) and added a third condition (e.g. medium cookie size).
Control of Extraneous Variables
As we have seen previously in the chapter, an extraneous variable is anything that varies in the context of a study other than the independent and dependent variables. In an experiment on the effect of expressive writing on health, for example, extraneous variables would include participant variables (individual differences) such as their writing ability, their diet, and their gender. They would also include situational or task variables such as the time of day when participants write, whether they write by hand or on a computer, and the weather. Extraneous variables pose a problem because many of them are likely to have some effect on the dependent variable. For example, participants’ health will be affected by many things other than whether or not they engage in expressive writing. This influencing factor can make it difficult to separate the effect of the independent variable from the effects of the extraneous variables, which is why it is important to control extraneous variables by holding them constant.
Extraneous Variables as “Noise”
Extraneous variables make it difficult to detect the effect of the independent variable in two ways. One is by adding variability or “noise” to the data. Imagine a simple experiment on the effect of mood (happy vs. sad) on the number of happy childhood events people are able to recall. Participants are put into a negative or positive mood (by showing them a happy or sad video clip) and then asked to recall as many happy childhood events as they can. The two leftmost columns of Table 20.1 show what the data might look like if there were no extraneous variables and the number of happy childhood events participants recalled was affected only by their moods. Every participant in the happy mood condition recalled exactly four happy childhood events, and every participant in the sad mood condition recalled exactly three. The effect of mood here is quite obvious. In reality, however, the data would probably look more like those in the two rightmost columns of Table 20.1. Even in the happy mood condition, some participants would recall fewer happy memories because they have fewer to draw on, use less effective recall strategies, or are less motivated. And even in the sad mood condition, some participants would recall more happy childhood memories because they have more happy memories to draw on, they use more effective recall strategies, or they are more motivated. Although the mean difference between the two groups is the same as in the idealized data, this difference is much less obvious in the context of the greater variability in the data. Thus one reason researchers try to control extraneous variables is so their data look more like the idealized data in Table 20.1, which makes the effect of the independent variable easier to detect (although real data never look quite that good).
| Idealized “noiseless” data | Realistic “noisy” data | ||
| Happy mood | Sad mood | Happy mood | Sad mood |
| 4 | 3 | 3 | 1 |
| 4 | 3 | 6 | 3 |
| 4 | 3 | 2 | 4 |
| 4 | 3 | 4 | 0 |
| 4 | 3 | 5 | 5 |
| 4 | 3 | 2 | 7 |
| 4 | 3 | 3 | 2 |
| 4 | 3 | 1 | 5 |
| 4 | 3 | 6 | 1 |
| 4 | 3 | 8 | 2 |
| M = 4 | M = 3 | M = 4 | M = 3 |
One way to control extraneous variables is to hold them constant. This technique can mean holding situation or task variables constant by testing all participants in the same location, giving them identical instructions, treating them in the same way, and so on. It can also mean holding participant variables constant, like the example above in which the researchers excluded participants from the study who were not hungry.
In principle, researchers can control extraneous variables by limiting participants to one very specific category of person, such as 20-year-old, heterosexual, female, right-handed change management majors. The obvious downside to this approach is that it would lower the external validity of the study—in particular, the extent to which the results can be generalized beyond the people actually studied. For example, it might be unclear whether results obtained with a sample of younger women would apply to older men. In many situations, the advantages of a diverse sample (increased external validity) outweigh the reduction in noise achieved by a homogeneous one.
Extraneous Variables as Confounding Variables
The second way that extraneous variables can make it difficult to detect the effect of the independent variable is by becoming confounding variables. A confounding variable is an extraneous variable that differs on average across levels of the independent variable (i.e., it is an extraneous variable that varies systematically with the independent variable). For example, in almost all experiments, participants’ intelligence quotients (IQs) will be an extraneous variable. But as long as there are participants with lower and higher IQs in each condition so that the average IQ is roughly equal across the conditions, then this variation is probably acceptable (and may even be desirable). What would be bad, however, would be for participants in one condition to have substantially lower IQs on average and participants in another condition to have substantially higher IQs on average.
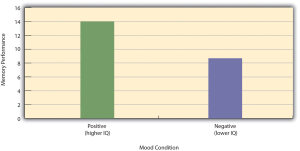
To confound means to confuse, and this effect is exactly why confounding variables are undesirable. Because they differ systematically across conditions—just like the independent variable—they provide an alternative explanation for any observed difference in the dependent variable. Figure 20.1 shows the results of a hypothetical study, in which participants in a positive mood condition scored higher on a memory task than participants in a negative mood condition. But if IQ is a confounding variable—with participants in the positive mood condition having higher IQs on average than participants in the negative mood condition—then it is unclear whether it was the positive moods or the higher IQs that caused participants in the first condition to score higher. One way to avoid confounding variables is by holding extraneous variables constant. For example, one could prevent IQ from becoming a confounding variable by limiting participants only to those with IQs of exactly 100. But this approach is not always desirable for reasons we have already discussed. A second and much more general approach—random assignment to conditions—will be discussed in detail shortly.
Treatment and Control Conditions
In psychological research, a treatment is any intervention meant to change people’s behavior, like the cookie size in the example above. To determine whether a treatment works, participants are randomly assigned to either a treatment condition, in which they receive the treatment, or a control condition, in which they do not receive the treatment. If participants in the treatment condition behave differently than than participants in the control condition, for example, they waste less or eat fewer cookies, then the researcher can conclude that the treatment works. This type of experiment is often called a randomized clinical trial.
There are different types of control conditions. In a no-treatment control condition. In other cases, respondents still receive some treatment, but a different treatment. For example, in the case of Werkman, Van Doorn & Van Ittersum (2022), participants either received small or large cookies, but there was no condition in which respondents did not receive cookies at all. Whether or not to include a completely ‘neutral’ control condition entirely depends on the experimenter’s goals, budget, and setup.
In some cases, especially in fields like medicine and psycholog and perhaps less so in business research, a no-treatment control condition might not be the best comparison, because of so-called placebo effects. A placebo is a simulated treatment that lacks any active ingredient or element that should make it effective, and a placebo effect is a positive effect of such a treatment. Many folk remedies that seem to work—such as eating chicken soup for a cold or placing soap under the bed sheets to stop nighttime leg cramps—are probably nothing more than placebos. Although placebo effects are not well understood, they are probably driven primarily by people’s expectations that they will improve. Having the expectation to improve can result in reduced stress, anxiety, and depression, which can alter perceptions and even improve immune system functioning (Price, Finniss, & Benedetti, 2008)[2].
Placebo effects are interesting in their own right, but they also pose a serious problem for researchers who want to determine whether a treatment works. Figure 20.2 shows some hypothetical results in which participants in a treatment condition improved more on average than participants in a no-treatment control condition. If these conditions (the two leftmost bars in Figure 20.2) were the only conditions in this experiment, however, one could not conclude that the treatment worked. It could be instead that participants in the treatment group improved more because they expected to improve, while those in the no-treatment control condition did not.
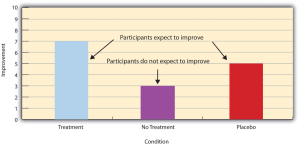
Fortunately, there are several solutions to this problem. One is to include a placebo control condition, in which participants receive a placebo that looks much like the treatment but lacks the active ingredient or element thought to be responsible for the treatment’s effectiveness. When participants in a treatment condition take a pill, for example, then those in a placebo control condition would take an identical-looking pill that lacks the active ingredient in the treatment (a “sugar pill”). The idea is that if participants in both the treatment and the placebo control groups expect to improve, then any improvement in the treatment group over and above that in the placebo control group must have been caused by the treatment and not by participants’ expectations. This difference is what is shown by a comparison of the two outer bars in Figure 20.2.
- Werkman, A., Van Doorn, J., Van Ittersum, K. (2022). Are you being served? Managing waist and waste via serving size, unit size, and self-serving. Food Quality and Preference, 99, 104568. https://doi.org/10.1016/j.foodqual.2022.104568. ↵
- Price, D. D., Finniss, D. G., & Benedetti, F. (2008). A comprehensive review of the placebo effect: Recent advances and current thought. Annual Review of Psychology, 59, 565–590. ↵
